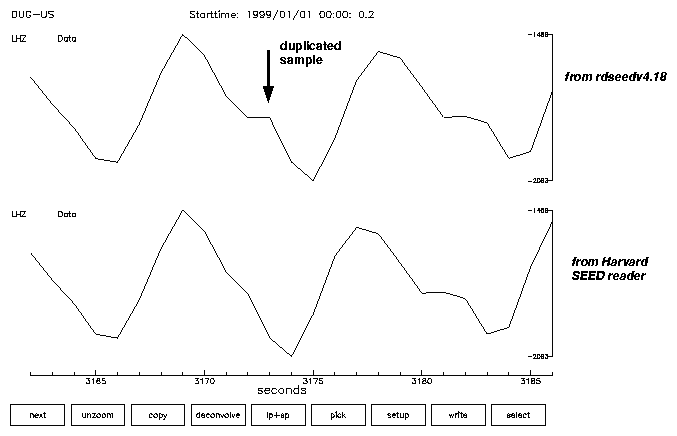
Timing problem introduced by NSN data compression.
Data from the NSN were requested and obtained from the IRIS DMC in SEED format. Extraction of these data using rdseed generates intermittent duplicate samples in the extracted time series. These duplicate samples occur at boundaries between compressed data records, and (in our analysis) correspond to an error in the initial data compression. We have developed a "fix" for this problem in our own SEED-reading software, to allow us to extract data without repeated samples.
The repetition of samples introduces a timing error corresponding to the sampling interval to the part of the time series that follows the repeated sample (always after the first data record in a continuous time series). The figure below shows an example of the problem and the 1 second timing error introduced by the repeated sample.