Of Proxies and Type II Errors

Of Proxies and Type II Errors
Tuesday, March 29, 2011
The McShane and Wyner (2011) paper has been officially published along with contributions from 13 discussants, the editor of the exchange and the rejoinder from the original authors. This collection of work is not new news for anyone who has followed the debate over reconstructions of global and hemispheric surface temperatures during the Common Era. The internet is splattered with news pieces, blog discussions and tweets about the work and the subsequent exchange. As such, I am not interested in providing any background on the work or weighing in on any of the back-and-forth arguments. The purpose of this post is simply to discuss my contribution to the discussion and to highlight a few unanswered questions that are of interest moving forward.
First and foremost, it is worth repeating the original paragraph of my discussion:
McShane and Wyner [(2011); hereinafter MW11] reiterate a well-known and central challenge of paleoclimatology: it is fraught with uncertainties and based on noisy observations. Decades of research have aimed at characterizing these uncertainties and interpreting proxies through laboratory experiments, field observations, theory, process-based modeling, cross-record comparisons, and indeed through statistical modeling and hypothesis testing. It is against this larger backdrop that the problem addressed by MW11 must be considered. Attempts to reconstruct global or hemispheric temperature indices and fields using multi-proxy networks are an outgrowth of many efforts in paleoclimatology, but represent relatively recent pursuits in the field. They provide neither the principal scientific evidence supporting climate-proxy connections, nor the most compelling, and the inference by MW11 that their own findings demonstrate a widespread failure in the predictive capacity of climate proxies is at odds with most other independent lines of proxy research.
In other words, many very smart people have spent a lot of time within the individual proxy communities collecting and analyzing their data. The determined connection between climate and a given proxy (and its associated uncertainties) stands on a great deal of research that often gets glossed over in the heated discussions about large-scale temperature reconstructions from multiproxy networks. I could spend a lot of time discussing the various explanations for this, but the important thing to keep in mind is that experiments like the ones performed by MW11 are by no means the principal way in which proxy-climate connections are established. This is worth remembering because there is a vast amount of insightful information in the proxy literature about the climatic interpretation of proxy records, not to mention the fact that research in these areas is itself just damned interesting science. It is of course hard to represent all of that science in a short discussion piece, but it certainly deserved mentioning before pursuing the more specific argument that I make in my discussion.
So what is the remaining point of my discussion? To make sense of my argument, it is necessary to understand two things: (1) the difference between the definition of pseudoproxies as it is applied in the paleoclimate literature and the one that was used by MW11; and (2) the nature of the hypothesis test that MW11 used to conclude that proxies were poor recorders of temperature.
See some of our earlier posts (here and here) for background on pseudoproxy experiments and how pseudoproxies are constructed. In a nutshell, the paleoclimate community constructs pseudoproxies as a combination of signal plus noise and varies the level of noise to achieve different signal-to-noise ratios. We believe this is the most representative way to mimic the combined signal and noise in real-world proxy records, although the white noise models that we have used to date are most certainly a simplification of the actual noise in proxy records. In contrast, MW11 simply define pure-noise time series as pseudoproxies. The difference between these two definitions is important for understanding the nature of the hypothesis that is tested when using one version of pseudoproxy or the other.
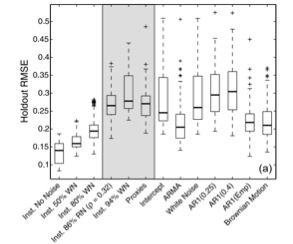
The basis of the MW11 hypothesis test can be boiled down into a single question: do climatic proxies perform better than random noise series at predicting Northern Hemisphere (NH) mean temperatures. If the answer is no, it may place doubt on the interpretation of proxies as historical recorders of temperature change. To attempt an answer to the question, MW11 used the Lasso regression method to first calibrate proxies on a section of the observed NH mean temperature index and then to predict (reconstruct) observed NH mean temperatures in a 30-year holdout block of the time series, i.e. a reserved portion of the time series that was not used in calibration. They generated ensemble statistics by redoing this experiment for a sliding series of 30-year holdout blocks across the entire NH temperature time series. What they found was that several different kinds of random noise series actually performed better than the proxies at predicting the collection of 30-year holdout blocks. My reproduction of these results can be found in a portion of the figure shown at the top of this post. Based on the results of these experiments, MW11 concluded that there was no statistical justification for interpreting the proxies as recorders of past temperature variability.
But not all tests are created equal. Depending on the hypothesis test that one constructs, the results can generate Type I (false positive) or Type II (false negative) errors. I wanted to see the results of the MW11 test for pseudoproxies that were known to contain temperature signals. The basis of my experiment asked whether time series known to contain temperature signals (perturbed with noise) would actually pass the MW11 test. To do this, I employed the other definition of pseudoproxies described above by taking local temperature time series from the gridded global temperature field and adding different levels of noise to the series. I then used these signal-plus-noise series in the same test that MW11 performed. As it turns out, random noise series still outperformed pseudoproxies known to contain temperature signals perturbed by noise levels approaching real-world levels (see the first five boxplots from the left in the figure at the top of this post). The important implication of this result is that proxies containing temperature signals are unlikely to outperform the pure-noise series in the MW11 test. This is a classic Type II error and suggests that the test performed in MW11 may not be appropriate for addressing how well proxies perform as recorders of past temperature variability.
So what’s next? This post is getting too long already, but it is worth pointing to a few questions moving forward. I mention several caveats about my own test in my discussion piece that deserve further attention. The dependence of my results on the way I sampled the global temperature field is worth exploring. McShane and Wyner also propose several additional pseudoproxy definitions in their rejoinder that deserve more investigation. Results may also depend on the different reconstruction methodologies that are used, including the difference between reconstructions that target the NH mean index and those that attempt to reconstruct spatial patterns in the global temperature field. The success of the pure-noise experiments is also undoubtedly dependent on the number of noise series that are used, and this dependence should be further tested because many proxy studies have only used a few tens of predictors for skillful NH temperature reconstructions. Perhaps most importantly, there is much to be gained from understanding why various noise models perform as well as they do in the MW11 test. Such insights may allow us to impose additional constraints to our regression techniques to improve them and to better characterize their uncertainties. In that regard, I will leave the last word to my colleague Alexey Kaplan, who concluded his own discussion piece as follows:
Modern analysis systems do not throw away observations simply because they are less skillful than other information sources: instead, they combine information. MW2011 experiments have shown that their multivariate regressions on the proxy data would benefit from additional constraints on the temporal variability of the target time series, for example, with an AR model. After proxies are combined with such a model, a test for a significance of their contributions to the common product could be performed.
PAPER REFERENCE: Smerdon, J.E. (2011), Discussion of: A Statistical Analysis of Multiple Temperature Proxies: Are Reconstructions of Surface Temperatures Over the Last 1000 Years Reliable?, Annals of Applied Statistics, 5(1), 76-79. [Complete AOAS Issue] [Supplementary Materials]
Figure 1a from Smerdon (2011) showing the cross-validated RMSE on 30-year hold out blocks for a subset of the original McShane and Wyner (2011) experiments and for newly completed experiments using the instrumental data perturbed with various levels of noise. The 86% red-noise experiment is considered to be representative of the average proxy predictor [Mann et al. (2007)] and compares well to the proxy result.

